* 지난 프로젝트 : goeden.tistory.com/35에서 생략된 코드 확인 가능
지난 프로젝트에 이어, 더 정확한 예측을 위해 렌더링 환경이미지를 추가로 입력해 보겠습니다. 학습 시에도 렌더링 환경이미지를 추가로 입력하고 테스트 시에도 렌더링 환경이미지를 추가로 입력합니다.
1. openGL을 활용하여 구(sphere)를 20,000개 렌더링한다.
2. 렌더링에서 무작위로 설정하는 속성 parameter 5개는 순서대로 R(red), G(green), B(blue), metallic(금속재질), roughness(표면의 거친 정도)를 나타내며, 이를 label로 저장한다.
3. 위에서 만든 구 이미지와 렌더링 환경이미지, label(parameter 값)을 train set으로 저장한다.
4. test set에 해당하는 1,000개의 구와 렌더링 환경이미지, 1,000쌍(5개씩)의 label을 렌더링-저장한다.
5. 20,000개의 구를 tensorflow를 활용하여 학습시킨다.
6. 학습시킨 모델을 가지고 1,000개의 구를 테스트하여 학습된 모델의 정확도를 파악한다.
dataset hierarchy
📁 pbr_1000_env (test용 구 렌더링 환경이미지)
ㄴ 구 렌더링 환경 이미지들(pbr_00000.jpg ~ pbr_00999.jpg)
📁 pbr_1000_full (test용 구 이미지)
ㄴ 구 이미지들(pbr_00000.jpg ~ pbr_00999.jpg)
📁 pbr_20000_env (training용 구 렌더링 환경이미지)
ㄴ 구 렌더링 환경 이미지들(pbr_00000.jpg ~ pbr_19999.jpg)
📁 pbr_20000_full (training용 구 이미지)
ㄴ 구 이미지들(pbr_00000.jpg ~ pbr_19999.jpg)
📄 pbr_1000_test.bin (test용 구 이미지들의 label / floating points (4bytes) / (1000, 5))
📄 pbr_20000_uniform.bin (training용 구 이미지들의 label / floating points (4bytes) / (20000, 5))
* 해당 데이터셋은 저의 저작물이 아니므로, 전달/배포가 불가한 점 양해바랍니다.
전처리
이전과 마찬가지로, 이미지와 라벨을 불러온다. 대신, 이번에는 렌더링 환경이미지가 있기 때문에 리스트를 하나 더 만들어야 한다. (원래의 구 이미지는 rendered_ds 리스트에, 원래의 라벨은 dataset_label 리스트에 넣었다.) 추가되는 부분의 코드는 다음과 같다.
env_ds = []
for i in range (0,20000):
filename = 'spheres\pbr_20000_env\pbr_' + str(i).zfill(5) + '.jpg'
image = pilimg.open(filename)
env_ds.insert(i, np.array(image))
env_ds = np.array(env_ds, dtype="float32")
env_ds /= 255.0test_env_ds.shape(1000, 128, 128, 3)
plt.imshow(test_env_ds[0])

모델 생성 및 학습
다중 입력을 받는 모델의 경우에는 아래와 같이 함수형으로 (functional API) 모델을 구축해주어야 한다. (ebbnflow.tistory.com/128)
input_r = Input(shape=(128,128,3))
input_e = Input(shape=(128,128,3))
input_c = concatenate([input_r, input_e]) #합성곱은 채널별로 따로 하기 때문에 먼저 합치고 집어넣어도 됨...!
conv1 = Conv2D(64, (3,3), activation='relu')(input_c)
mp1 = MaxPooling2D((2,2))(conv1)
conv2 = Conv2D(128, (3,3), activation='relu')(mp1)
mp2 = MaxPooling2D((2,2))(conv2)
conv3 = Conv2D(256, (3,3), activation='relu')(mp2)
mp3 = MaxPooling2D((2,2))(conv3)
conv4 = Conv2D(512, (3,3), activation='relu')(mp3)
mp4 = MaxPooling2D((2,2))(conv4)
conv5 = Conv2D(512, (3,3), activation='relu')(mp4)
fltn = Flatten()(conv5)
den1 = Dense(1024, activation='relu')(fltn)
den2 = Dense(1024, activation='relu')(den1)
output = Dense(5, activation='sigmoid')(den2)
model = Model(inputs=[input_r, input_e], outputs=output)
optimizer = tf.keras.optimizers.Adam(lr=0.0001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
그리고 모델을 학습시키기 위해 아래와 같이 모델의 입력을 리스트처럼 설정해야 한다.
EPOCHS = 100
model.fit(x=[rendered_ds, env_ds], y=dataset_label,validation_split=0.2, epochs=EPOCHS, verbose=2)

테스트
모델 학습이 끝나면, 마찬가지로 test 데이터셋 1,000개를 불러와 모델의 성능을 평가한다. 기존 이미지 데이터는 test_rendered_ds라는 리스트에, 기존 라벨 데이터는 test_label 리스트에, 새로운 테스트용 구 이미지의 렌더링 환경이미지는 test_env_ds 리스트에 불러왔다. test_env_ds 부분의 코드는 다음과 같다.
test_env_ds = []
for i in range (0,1000):
filename = 'spheres\pbr_1000_env\pbr_' + str(i).zfill(5) + '.jpg'
image = pilimg.open(filename)
test_env_ds.insert(i, np.array(image))
test_env_ds = np.array(test_env_ds, dtype="float32")
test_env_ds /= 255.0
test 데이터셋의 라벨을 예측해보자. 마찬가지로 입력은 두 개이다.
test_predictions = model.predict([test_rendered_ds, test_env_ds])
test_predictions.shape(1000, 5)
test 데이터셋의 실제 라벨과 모델이 예측한 라벨을 비교해 보았다.
testdata_param1 = np.array(testdata_label).T[0]
testdata_param2 = np.array(testdata_label).T[1]
testdata_param3 = np.array(testdata_label).T[2]
testdata_param4 = np.array(testdata_label).T[3]
testdata_param5 = np.array(testdata_label).T[4]
testpred_param1 = np.array(test_predictions).T[0]
testpred_param2 = np.array(test_predictions).T[1]
testpred_param3 = np.array(test_predictions).T[2]
testpred_param4 = np.array(test_predictions).T[3]
testpred_param5 = np.array(test_predictions).T[4]
먼저 첫 번째 파라미터 R(red)


이전 결과(좌측)와 비교해 보면 예측값이 많이 정확해진 것을 알 수 있다.
두 번째 파라미터 G(green)


세 번째 파라미터 B(blue)
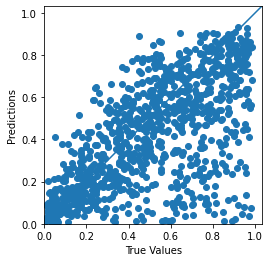

네 번째 파라미터 metallic


다섯 번째 파라미터 roughness


원래도 비교적 정확한 예측을 했던 roughness 파라미터 값도 더 정확해진 모습이다.
마지막으로, error 값을 히스토그램으로도 출력해 보았다. 이 역시 이전과는 다르게 0.0 부근, 즉 더 적은 오차값에 많은 분포를 보인다. (이를 표시하기 위해 세로축의 count 범위가 400까지 늘어난 것을 참고하면 좋다.)


다음 프로젝트에서는, 어떤 것을 할지 아직 모르겠어요. 한동안 코로나 바이러스 때문에 연구실을 못 나가서... 내일 오랜만에 방문할 예정입니다!
'College Study > Deep Learning' 카테고리의 다른 글
| [Tensorflow] 이미지/AutoEncoder/UNet - 초록색 잎을 보라색으로 바꾸기 (1) | 2021.03.05 |
|---|---|
| [Tensorflow] 이미지/AutoEncoder/UNet - 오토인코더로 그림 인코딩, 디코딩 하기 (3) | 2021.03.03 |
| [Tensorflow] 이미지/CNN/회귀 - 무작위로 렌더링한 구의 속성 학습하기 (7) | 2020.11.18 |
| [Tensorflow] 환경 구축 (0) | 2020.11.07 |
| [Visualization Lab] 인공지능/머신러닝/딥러닝 이론, 기초 공부법 (0) | 2020.10.15 |



댓글