visualization lab에서의 첫번째 deep learning (딥러닝) 프로젝트를 소개합니다. 우선 이 프로젝트가 어떤 프로젝트인지부터 간략하게 설명하겠습니다.
1. openGL을 활용하여 구(sphere)를 20,000개 렌더링한다.
2. 렌더링에서 무작위로 설정하는 속성 parameter 5개는 순서대로 R(red), G(green), B(blue), metallic(금속재질), roughness(표면의 거친 정도)를 나타내며, 이를 label로 저장한다.
3. 위에서 만든 구 이미지와 label(parameter 값)을 train set으로 저장한다.
4. test set에 해당하는 1,000개의 구와 1,000쌍(5개씩)의 label을 렌더링-저장한다.
5. 20,000개의 구를 tensorflow를 활용하여 학습시킨다.
6. 학습시킨 모델을 가지고 1,000개의 구를 테스트하여 학습된 모델의 정확도를 파악한다.
1~4번에 해당하는 데이터셋은 연구실에 계신 대학원생 선배가 만들어 주셨습니다. 저는 모델을 만들고, 학습시키고, 새로운 테스트 셋으로 모델을 평가하는 것을 수행해보았습니다.
dataset hierarchy
📁 pbr_1000_full (test용 구 이미지)
ㄴ 구 이미지들(pbr_00000.jpg ~ pbr_00999.jpg)
📁 pbr_20000_full (training용 구 이미지)
ㄴ 구 이미지들(pbr_00000.jpg ~ pbr_19999.jpg)
📄 pbr_1000_test.bin (test용 구 이미지들의 label / floating points (4bytes) / (1000, 5))
📄 pbr_20000_uniform.bin (training용 구 이미지들의 label / floating points (4bytes) / (20000, 5))
* 해당 데이터셋은 저의 저작물이 아니므로, 전달/배포가 불가한 점 양해바랍니다.
전처리
PIL.Image 를 사용하여 이미지를 불러오고, numpy 를 사용하여 이미지 파일을 numpy 배열로 변환한다. (matplotlib 를 사용하여 배열을 image로 다시 출력하여, 배열에 제대로 입력이 되었는지 확인하였다.)
import PIL.Image as pilimg
import numpy as np
import matplotlib.pyplot as plt
'dataset'이라는 빈 리스트를 만들어 train set 이미지 20,000개를 불러온다. (blog.naver.com/ji0eeeee/221534172513)
dataset = []
for i in range (0,20000):
filename = 'spheres\pbr_20000_full\pbr_' + str(i).zfill(5) + '.jpg'
image = pilimg.open(filename)
dataset.insert(i, np.array(image))zfill 은 문자열을 5자리수로 맞추어 빈 자리에 0을 넣기 위해 사용하였다. (c10106.tistory.com/2216) 해당 프로그램과 같은 위치에 있는 폴더 'spheres'에 접근하여 'filename'을 이름으로 가진 이미지들을 하나씩 불러온다. pilimg.open 을 사용하면 파일 이름으로 이미지를 불러올 수 있다. 해당 이미지를 numpy array로 변환하여 'dataset' 리스트에 넣어준다.
numpy array(이미지 정보)를 요소로 가지고 있는 'dataset' 리스트도 numpy array로 변환한다. 이 때, 이미지 정보를 0과 1 사이로 정규화 해주기 위해 값을 255로 나누어준다. (해당 프로젝트에서는 생략해도 같은 결과를 출력하긴 하지만, 색 정보를 입력할 때에는 정규화를 해주는 것이 좋다.) .shape 을 실행하면 numpy array의 크기(모양)을 출력할 수 있다. (nittaku.tistory.com/109) 또한 아무 요소나 하나를 matplotlib.pyplot.imshow( ) 로 출력하면 해당 이미지를 확인할 수 있다.
dataset = np.array(dataset)
dataset /= 255.0
dataset.shapeplt.imshow(dataset[0])
이번에는 dataset의 label을 불러오도록 하자. label 값을 binary 파일로 저장하였기 때문에, struct 를 사용해 binary 파일을 읽어 왔다.
import struct
마찬가지로 빈 리스트 'dataset_label'을 만들어 label 값들을 불러왔다. 위의 hierarchy에서 언급했듯이, 해당 binary 파일은 floating point (4bytes)형 값이 20,000 x 5의 형태로 들어있다.
dataset_label = []
with open('spheres\pbr_20000_uniform.bin', 'rb') as f:
data = f.read()
for i in range (20000):
params = []
temp = struct.unpack('fffff', data[i * 20: (i+1) * 20])
dataset_label.insert(i, temp)(pythonstudy.xyz/python/article/206-파일-데이타-처리) (docs.python.org/3/library/struct.html)
이렇게 만들어진 리스트도 numpy.array 로 변형을 해준다. .shape 을 통해 크기(모양)을 확인할 수 있다. label도 요소 하나를 출력해 확인해보자.
dataset_label = np.array(dataset_label)
dataset_label.shapedataset_label[0]
모델 생성
이미지를 convolutional 인공신경망(CNN)으로 학습시킬 예정이기 때문에 'tensorflow tutorial: 합성곱 신경망'과,
합성곱 신경망 | TensorFlow Core
Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도 불구하고 공식 영문 문서의 내용과 일치하지 않을 수
www.tensorflow.org
classification(분류)가 아닌 rendering parameter 값 (연속된 값)을 예측할 것이기 때문에 'tensorflow tutorial: 회귀'를 참고하였다.
자동차 연비 예측하기: 회귀 | TensorFlow Core
Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도 불구하고 공식 영문 문서의 내용과 일치하지 않을 수
www.tensorflow.org
tensorflow.keras 와 tensorflow.keras.layers 를 활용하여 모델을 빌드한다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
build_model() 함수를 정의하여 model을 만들고, optimizer를 설정하고, compile까지 한번에 하도록 설정하였다.
def build_model():
model = keras.Sequential([
layers.Conv2D(32, (3,3), activation='relu', input_shape=(128,128,3)),
layers.MaxPooling2D((2,2)),
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(128, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(256, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(512, (3,3), activation='relu'),
layers.Flatten(),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(5, activation='sigmoid')
])
optimizer = tf.keras.optimizers.Adam(lr=0.0001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model모델 구성 :
1) 128px * 128px * 3 color채널 데이터(이미지)를 32개의 3x3 필터(kernel)로 합성곱(convolution) 실행
2) max pooling을 통해 이미지 사이즈를 축소 (노드의 수는 증가하게 됨)
3) 1)~2)의 과정을 반복, 이 때 필터의 개수는 2배로 증가시키는 것이 일반적
4) 이미지의 크기가 4*4 또는 6*6 정도로 작아지면 합성곱-pooling의 반복을 중단
5) 이미지 데이터를 flatten (일차원 배열로 변형)
6) dense layer를 통해 늘어난 node의 수를 축소, 이 때의 parameter는 적절한 크기로 설정 (이 프로그램에서는 flatten시 parameter 크기가 100만개 이상이어서 512로 설정)
7) 마지막 dense layer는 출력 노드를 5개로 설정(label이 5개의 렌더링 parameter 값이기 때문), activation 함수는 sigmoid 를 사용하여 출력 값을 0~1 사이의 값으로 고정
(www.tensorflow.org/api_docs/python/tf/keras/Sequential)
(www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D)
(www.tensorflow.org/api_docs/python/tf/keras/layers/MaxPool2D)
(www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten)
(www.tensorflow.org/api_docs/python/tf/keras/layers/Dense)
(www.tensorflow.org/api_docs/python/tf/keras/activations/relu)
(www.tensorflow.org/api_docs/python/tf/keras/activations/sigmoid)
* 이 블로그에서 CNN, maxpooling 설명 보기 (클릭)
* 이 블로그에서 sigmoid, ReLU 설명 보기 (클릭)
optimizer는 adam 을 사용하였고, learning rate(lr)은 통상적으로 사용하는 값보다 작게(0.0001) 설정하였다.
(www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam)
회귀분석을 사용할 것이기 때문에 컴파일 시 loss function을 mse , metrics를 mae , mse 로 설정하였다.
(https://www.tensorflow.org/api_docs/python/tf/keras/Model#compile)
(www.tensorflow.org/api_docs/python/tf/keras/losses/MSE)
(www.tensorflow.org/api_docs/python/tf/keras/metrics)
(www.tensorflow.org/api_docs/python/tf/keras/losses/MAE)
'build_model()'은 컴파일된 모델을 반환한다.
모델의 summary를 출력해보자.
model = build_model()
model.summary()
학습
이제 학습을 시키면 된다. (https://www.tensorflow.org/api_docs/python/tf/keras/Model#fit)
EPOCHS = 100
model.fit(dataset, dataset_label,validation_split=0.2, epochs=EPOCHS, verbose=2)epochs(training 횟수)는 100으로 설정했다. 사실 이 프로그램의 경우 60회 이상 넘어가면 loss 값이 별로 줄어들지 않는다. (특히 validation) 하지만 그냥 100으로 했다.
validation_split 을 0.2로 잡아 training set을 training set과 validation set으로 나누었다. validation set은 training set으로 모델이 학습될 때마다 모델에 test 용으로 사용되며, validation loss값을 측정하여 training set에 모델이 overfitting되기 전에 학습을 중지할 수 있도록 하는 역할을 한다.
verbose를 2로 설정하면, training이 진행되는 도중에 소요시간, loss 값 등을 출력하여 확인이 가능하다.
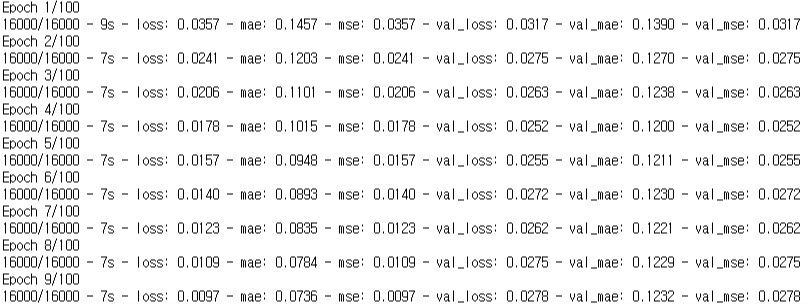
loss 값이 점점 줄어야 제대로 학습이 되고 있는 것이다.

학습이 완료될 쯤엔 정말 작은 loss 값을 보인다.
테스트
모델 학습이 끝나면, test 데이터셋 1,000개를 불러와 모델의 성능을 평가한다. 이미지 데이터와 label을 불러온다.
for i in range (0,1000):
filename = 'spheres\pbr_1000_full\pbr_' + str(i).zfill(5) + '.jpg'
image = pilimg.open(filename)
testdata.insert(i, np.array(image))
plt.imshow(testdata[0]) #확인용
testdata = np.array(testdata)
testdata /= 255.0
testdata_label = []
with open('spheres\pbr_1000_test.bin', 'rb') as f:
data = f.read()
for i in range (1000):
params = []
temp = struct.unpack('fffff', data[i * 20: (i+1) * 20])
testdata_label.insert(i, temp)
testdata_label = np.array(testdata_label)
학습을 시킨 모델로 새로운 1,000개의 이미지 데이터셋의 렌더링 파라미터(RGB, metallic, roughness)를 예측할 수 있다.
(https://www.tensorflow.org/api_docs/python/tf/keras/Model#predict)
test_predictions = model.predict(testdata)
1,000개의 테스트 데이터셋의 실제 라벨과 방금 모델을 통해 예측한 값을 비교해보려고 한다. 단, 1,000개의 이미지마다 5개의 파라미터 값이 있기 때문에 1,000x5 크기의 라벨들을 열별로 나눠서 1,000x1씩 5번 비교한다. 즉, 파라미터 별로 얼마나 잘 예측했는지 결과를 확인한다. 그러기 위해 라벨과 예측값을 분리시킨다.
testdata_param1 = np.array(testdata_label).T[0]
testdata_param2 = np.array(testdata_label).T[1]
testdata_param3 = np.array(testdata_label).T[2]
testdata_param4 = np.array(testdata_label).T[3]
testdata_param5 = np.array(testdata_label).T[4]
testpred_param1 = np.array(test_predictions).T[0]
testpred_param2 = np.array(test_predictions).T[1]
testpred_param3 = np.array(test_predictions).T[2]
testpred_param4 = np.array(test_predictions).T[3]
testpred_param5 = np.array(test_predictions).T[4]
플롯을 찍어 시각적으로 비교해보자. 첫번째 파라미터 (RGB-red) 비교:
plt.scatter(testdata_param1, testpred_param1)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
두번째 파라미터 (RGB-green) 비교:
plt.scatter(testdata_param2, testpred_param2)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])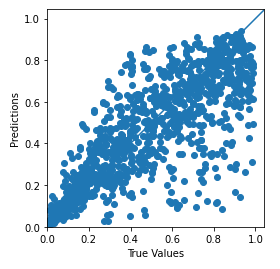
세번째 파라미터 (RGB-blue) 비교:
plt.scatter(testdata_param3, testpred_param3)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
네번째 파라미터 (metallic) 비교:
plt.scatter(testdata_param4, testpred_param4)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
다섯번째 파라미터 (roughness) 비교:
plt.scatter(testdata_param5, testpred_param5)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])다른 파라미터에 비해서 예측값이 정확해보인다. 육안으로 보기에도 구분이 쉬운 요소이기 때문이다.

마지막으로, error 값을 히스토그램으로 나타내본다. 전체 값을 그대로 넣어 플롯을 찍으면, 파라미터 별로 오차값을 따로 나타내준다.
error = test_predictions - testdata_label
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error")
_ = plt.ylabel("Count")
오차 0.0 (정확히 예측) 근처 분포가 가장 많다. 확인 결과, 꽤 정확한 예측값을 계산할 수 있는 유의미한 모델로 학습되었음을 알 수 있다.
다음 프로젝트에서는, 더 정확한 예측을 할 수 있게끔 렌더링 환경이미지를 추가로 입력할 예정입니다.
'College Study > Deep Learning' 카테고리의 다른 글
| [Tensorflow] 이미지/AutoEncoder/UNet - 초록색 잎을 보라색으로 바꾸기 (1) | 2021.03.05 |
|---|---|
| [Tensorflow] 이미지/AutoEncoder/UNet - 오토인코더로 그림 인코딩, 디코딩 하기 (3) | 2021.03.03 |
| [Tensorflow] 이미지/CNN/다중입력 - 무작위로 렌더링한 구의 속성 학습하기 (0) | 2021.01.14 |
| [Tensorflow] 환경 구축 (0) | 2020.11.07 |
| [Visualization Lab] 인공지능/머신러닝/딥러닝 이론, 기초 공부법 (0) | 2020.10.15 |


댓글